이제 본격적인 명령어, 인스트럭션 단계로 넘어가겠습니다. 각 인스트럭션 유형별로, 그 종류와 기능, 최적화된 모습 등을 이야기하겠습니다. 이번 포스팅에서는 가장 먼저, MOV 클래스를 다루도록 하겠습니다. 우리가 메모리와 레지스터를 이용하면서 프로그램을 동작시킬 때, 가장 기본이 되는것은 적재와 저장입니다. 이용할 자원을 메모리에 띄우고, 그리고 그 결과 값을 다시 저장하고, 또 이는 레지스터에서도 마찬가지로 적용되니, 모든 프로그램에서 사용하는 가장 기초적인 명령어가 됩니다. 오늘은 이를 집중적으로 알아볼 겁니다.
MOV클래스
먼저 오리지널 MOV 계열 인스트럭션은, 데이터를 소스위치에서 목적지로 옮길 때, 어떤 변화도 거치지 않고 복사합니다. 즉 소스가 표현하는 값의 범위와, 목적지가 받고자 하는 값의 범위 등을 고려하지 않고, 그저 명령이 들어온대로, 동작할 뿐입니다. 해당 인스트럭션의 종류로는 movb, movw, movl, movq가 있습니다. b w l q 는 각각 바이트(Byte), 워드(word), 더블워드(Double word(고급 언어에서는 int로 많이 보셨을 겁니다.)), 쿼드워드(Quad word)를 의미합니다. 기초 단위인 바이트와, 2바이트 단위로 워드(2바이트)를 이루고, 이 워드가 2개 연속되면 더블워드(4바이트), 4개 연속되면 쿼드워드(8바이트)를 형성합니다. 네 명령어는 모두 mov의 기능을 가지나, 복사하는 범위에 따라서 아래와 같이 구분합니다. 영어의 접미사와 같은 개념입니다. 우리가 동작시키기고 하자는 명령의 종류는 인스트럭션 명칭으로(MOV 등), 그리고 그 범위의 지정을 뒤에 b w l q 등과 같은 알파벳을 통해 한정시킵니다.

해당 MOV 클래스 명령어에서는 몇가지 규칙이 존재합니다. 소스 오퍼랜드, 그러니까 우리가 복사해갈 주체의 경우에는, 상수, 레지스터 저장 값, 메모리 저장값을 표시합니다. 그리고 목적 오퍼랜드, 우리가 복사하여 보관할 대상의 경우, 레지스터와 메모리 주소 위치로 한정합니다. 그리고 이는 어셈블리 코드로 나타내면, MOV S D 로 나타냅니다. 소스인 S를 목적지인 D(주소)로 복사함을 의미합니다. 당연히 D는 목적지가 되어야 하므로, 상수 등의 즉시값은 받을 수 없습니다.
또한, 소스와 목적지 모두가 메모리여서는 안됩니다. 간단히 설명하자면, 무조건적으로 레지스터를 거쳐야 함이 규칙인데, 여러 사유로 인해 이 규칙이 형성되었습니다. 먼저 메모리에 접근한다 함은, 주소 계산과 더불어, 캐시와 메모리 버스로의 액세스가 필요합니다. 그러나 한 인스트럭션에서 두개의 메모리 오퍼랜드가 들어갈 경우, CPU에서는 두 주소를 동시 계산하고, 메모리 또한 두번의 읽기(또는 쓰기까지) 동작을 시행해야합니다. 이는 상당한 비용적 비효율을 야기합니다. 또한 성능적으로도, 레지스터 기반 연산은 CPU에 속해 있으므로 메모리에 비해 접근성과 그 효율이 압도적으로 빠릅니다. 따라서, 메모리 간 연산으로 실행할 경우 파이프라인 설계 자체나, 성능 최적화에 상당한 악영향을 끼칠 수 있습니다. 그리고 현재 다루는 x86 체제는, amd와 달리 가변 길이 인코딩이라는 기법을 채용하고 있습니다. 향후 다루게 될 내용이니 간단히 이야기하자면, 양 피연산자 모두 메모리가 될 경우, 이전에 이야기했던 주소 지정 모드(스케일링이나 오프셋 등)를 두번 거쳐야하기 때문에, 결정적으로 명령어 길이가 매우 늘어나 복잡성을 야기합니다. 이러한 사유로 x86 체제에서는 최대 한개까지만 메모리가 피연산자로 지정되도록 강제하고 있습니다. 그렇기에, 메모리에서 메모리로 옮기는 동작을 설계할 경우, 한번은 레지스터를 경유하도록 설계해야합니다. 다만 예외적으로 SSE(다중 데이터 병렬 처리)나 AVX(SSE의 확장 버전)와 같은 벡터 명령어는 메모리간 연산이 가능합니다.
이 MOV 명령어는 지정된 범위를 복사한다 했습니다. 아래 그림을 통해 정확한 예시를 확인할 수 있습니다. 예를 들어서 %rax 레지스터에 $0x0011223344556677을 복사했다고 가정하겠습니다. 그리고 -1을 mov로 똑같이 %rax 쪽으로 복사할 건데, 여기서 중요한건 바이트까지만, 즉, movb $-1 %al로 -1의 바이트 영역인 ...FF 까지만 복사해오는겁니다. 이 경우 어떻게 될까요? 아래 예시를 통해 알 수 있는데, %rax 관점에서는 최종적으로 112233445566FF의 값을 가지게 됩니다. 즉, 목적지의 모든 범위를 덮어 쓰는 것이 아닌, 목적지 내에서, 명령어가 지시한 범위까지만 덮어씀을 의미합니다. 마찬가지로 movw에서는 뒤 네자리까지, l 과 q는 각각 절반과 전체를 F로 채우는 것을 확인할 수 있습니다. 다만, movl이 조금 다른 양상을 띕니다. movl로 데이터를 복사할 경우, 상위 4바이트가 모두 0으로 채워집니다. 이는 32비트 체계에서 64비트 체계로 컴퓨터 환경이 확장되면서, 동시에 64비트 환경에서 32비트 프로그램을 문제 없이 동작시키기 위한, 레거시 호환성을 위해 형성된 규칙입니다. 상위 값을 0으로 클리어 함으로, 32비트 연산을 안전하게 사용할 수 있어 채용되었습니다.
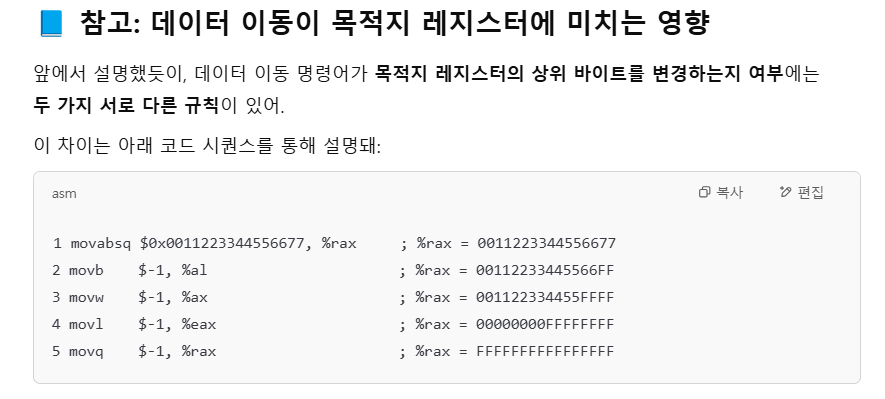
확장 데이터 이동 인스트럭션
앞서, 기본적인 MOV는 별도의 전환 없이, 접미사로 붙는 단위 그대로 복사하여 소스로부터 목적지로 옮긴다 하였습니다. 그리고 그 결과로 상단의 그림과 같이, 인스트럭션 단위까지만 덮어씌워지는 것을 볼 수 있었죠. 하지만 만약, 우리가 어떤 작은 값을, 레지스터 전체에 저장하고자 하는 의도를 가지고 있다면 어떨까요? 만약 전환 없이 그대로 복사만 해버린다면, 원본 값에, 덮어쓴 값이 혼동되어 엉뚱한 값이 출력될 수 있습니다. 당장 상단의 예시만 보아도, -1을 특정 범위 내로만 덮어씌워 FFFFFF.. 이 아닌 00112233...FF 로 덮어씌워짐을 확인할 수 있었습니다. 그렇다면, 완전히 그 레지스터를 통째로 덮어쓰는 인스트럭션엔 무엇이 있을까요? 먼저 단순히 0으로 덮어씌우는 방식이 있고, 상위 비트를 부호로 간주하여, 상위 비트로 채우는 방식이 있습니다. 그리고 이들은, 확장의 개념이므로, 소스와 목적지의 오퍼랜드 크기가 각각 다릅니다. 따라서 접미사도 두개를 전달받습니다.
단순히 0으로 덮어 씌우는 방식, Zero Extension 기법은 MOVZ 계열 클래스로 존재합니다. 말 그대로, 소스의 범위를 벗어나는 영역부터 목적지의 범위까지 모든 잔여 바이트를 0으로 채우는 기법입니다. 아래와 같이, movz와 함께 소스의 크기, 목적지의 크기를 각각 접미사로 붙여줍니다. 예를 들어 movbl의 경우 바이트인 소스를 더블 워드까지 0으로 확장 시키겠다는 인스트럭션을 의미합니다. 해당 명령어에서는 movzlq는 존재하지 않음을 확인할 수 있습니다. 4바이트(32비트)인 더블 워드는 8바이트(64비트)쿼터워드로 확장될 때, 그냥 mov로 확장해도 위에서 언급한 정책에 의해, 자동으로 0으로 확장되기 때문입니다.
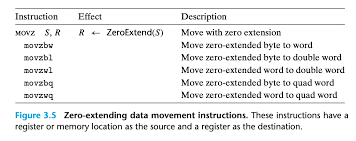
Sign Extension 기법인 MOVS의 경우, 말 그대로 부호를 반영하기 위한 확장 기법입니다. 위의 0 확장 기법은 0으로만 덮어 씌우기 기 때문에, unsigned, 부호가 없는 양수 값으로 고정되는 기법입니다. 만약 본인이 음수 또한 반영하고자 하는 경우, 또는 부호를 그대로 반영하고자 하는 경우, 이 MOVS 인스트럭션을 고민해 볼 수 있을 겁니다. 이 또한 두 오퍼랜드의 단위를 접미사로 받으며, 소스의 가장 앞 비트를 부호 비트로 인식합니다. 여기서 중요합니다. MOVS 계열은 결과를 sign으로 반환할 뿐, 소스가 sign인지 아닌지는 신경쓰지 않습니다. 쉽게 예를 들어보자면, 255를 부호 확장 한다고 생각해보겠습니다. 만약 0 확장이었다면, 목적지 크기에 따라 0000...1111 1111로 알맞게 복사되었을 것입니다. 하지만, MOVS 계열을 사용했다면 어떻게 될까요? movs에서 소스가 b, 바이트 였다면, 상위 비트가 1이니, 이를 그대로 전체에 복사합니다. 그렇다면 목적지로 복사되어 확장된 결과값은 1111 111.....로 16진수로 표현하면 FFFFF..... 이 될 것입니다. 즉 unsign인 값을 복사할 경우, 의도하지 않은 값이 도출될 수 있다는 특징을 보입니다. 괜히 초보에게 함부로 어셈블리 코드를 다루지 말라 하는게 아닌 것 같습니다.

'CS' 카테고리의 다른 글
| [CSAPP] 3챕터 - 프로그램의 기계수준 표현(7) - 조건 연산 인스트럭션 (1) | 2025.09.24 |
|---|---|
| [CSAPP] 3챕터 - 프로그램의 기계수준 표현(6) - 산술 연산 인스트럭션 (0) | 2025.09.10 |
| [CSAPP] 3챕터 - 프로그램의 기계수준 표현(4) - 오퍼랜드 (0) | 2025.09.06 |
| [CSAPP] 3챕터 - 프로그램의 기계수준 표현(3) - 스택 프레임 규칙 (0) | 2025.09.02 |
| [CSAPP] 3챕터 - 프로그램의 기계수준 표현(2) - 레지스터의 종류 (2) | 2025.08.10 |